Installing KNIME Analytics Platform
| For step-by-step videos on how to install KNIME Analytics Platform, please take a look at our KNIMETV YouTube channel. |
-
Go to the download page on the KNIME.com website to start installing KNIME Analytics Platform.
-
The download page shows three tabs which can be opened individually:
-
Register for Help and Updates: here you can optionally provide some personal information and sign up to our mailing list to receive the latest KNIME news
-
Download KNIME: this is where you can download the software
-
Getting Started: this tab gives you information and links about what you can do after you have installed KNIME Analytics Platform
-
-
Now open the Download KNIME tab and click the installation option that fits your operating system.
Notes on the different options for Windows:
-
The Windows installer extracts the compressed installation folder, adds an icon to your desktop, and suggests suitable memory settings.
-
The self-extracting archive simply creates a folder containing the KNIME installation files. You don’t need any software to manage archiving.
-
The zip archive can be downloaded, saved, and extracted in your preferred location on a system to which you have full access rights.
 Figure 1. KNIME Analytics Platform versions
Figure 1. KNIME Analytics Platform versions
-
-
Read and accept the privacy policy and terms and conditions. Then click Download.
-
Once downloaded, proceed with installing KNIME Analytics Platform:
-
Windows: Run the downloaded installer or self-extracting archive. If you have chosen to download the zip archive instead, unpack it to a location of your choice. Run
knime.exeto start KNIME Analytics Platform. -
Linux: Extract the downloaded tarball to a location of your choice. Run the
knimeexecutable to start KNIME Analytics Platform. -
Mac: Double click the downloaded dmg file and wait for the verification to finish. Then move the KNIME icon to Applications. Double click the KNIME icon in the list of applications to launch KNIME Analytics Platform.
-
| Also check the KNIME Quickstart Guide and the KNIME Workbench Guide. |
Configuration settings and knime.ini file
When installing KNIME Analytics Platform, configuration settings are set to their defaults, and they can later be changed in the knime.ini file. The configuration settings, i.e. options used by the Java Virtual Machine when KNIME Analytics Platform is launched, range from memory settings to system properties required by some extensions.
You can find knime.ini in the installation folder of KNIME Analytics Platform.
On MacOS: To locate knime.ini on MacOS, open Finder and navigate to your installed Applications.
Next, right click the KNIME application, select Show Package Contents in the menu, and navigate to Contents → Eclipse.
|
The knime.ini file can be edited with any plaintext editor, such as Notepad (Windows), TextEdit (MacOS) or gedit (Linux).
Allocating memory in knime.ini file
The entry -Xmx1024m in the knime.ini file specifies how much memory KNIME Analytics Platform is allowed to use.
The setting for this value will depend on how much memory is available in your machine.
KNIME recommends setting it to approximately one half of your available memory, but you can modify the value based on your needs.
For example, if your computer has 16 GB of memory, you might set the entry to -Xmx8192m.
Installing Extensions and Integrations
If you want to add capabilities to KNIME Analytics Platform, you can install extensions and integrations. The available extensions range from free open source extensions and integrations provided by KNIME to free extensions contributed by the community and commercial extensions including novel technology nodes provided by our partners.
The KNIME extensions and integrations developed and maintained by KNIME contain deep learning algorithms provided by Keras, high performance machine learning provided by H2O, big data processing provided by Apache Spark, and scripting provided by Python and R, just to mention a few.
Install extensions by:
-
Clicking File on the menu bar and then Install KNIME Extensions…. The dialog shown in Figure 2 opens.
-
Selecting the extensions you want to install
-
Clicking "Next" and following the instructions
-
Restarting KNIME Analytics Platform
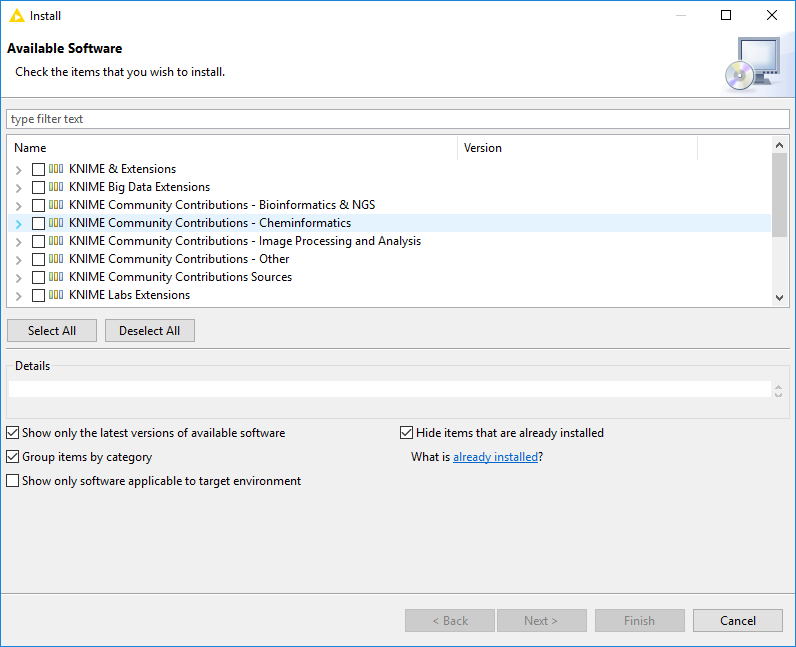
The Install KNIME Extensions menu provides the extensions that are available via the update sites you have enabled.
| For more information, take a look at our video on How to Install Extensions in KNIME Analytics Platform. Also see the Extensions and Integrations Guide. |
Updating KNIME Analytics Platform and Extensions
It is good to make sure that you always use the latest version of KNIME Analytics Platform and its extensions.
Do this by:
-
Clicking File → Update KNIME…. In the dialog that opens, select the available updates you want to install and then click Next.
-
Proceed by following the instructions. KNIME Analytics Platform has to be restarted in order to apply the updates.
Update Sites
The Update Sites are where KNIME retrieves additional software in the form of extensions as well as updates. To see or edit the available update sites, select File → Preferences → Install/Update → Available Software Sites.
Default Update Sites
These four updates sites are provided by KNIME and are always available:
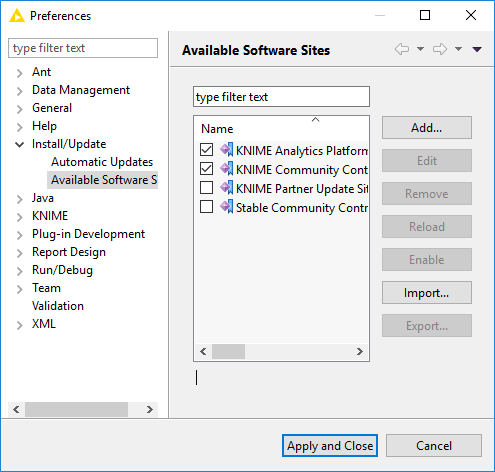
Figure 3. Available Update Sites
|
|
KNIME Analytics Platform 3.7 Update Site and KNIME Community Contributions are enabled by default.
Adding External Update Sites
To install extensions that are not part of the above update sites, click Add to manually add the relevant update site, inserting the Name and Location as shown in Figure 4.
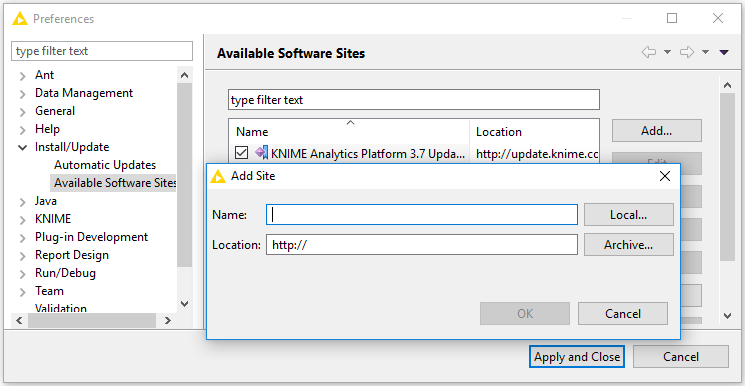
After adding a new update site you will see it listed in the Available Software Sites. You must now enable it by selecting it from the list.
Adding Local Update Sites
If your working environment has limited internet access or you receive an error message “Proxy Authentication Required” when connecting to a remote update site (provided by a URL), you can install extensions from a local zip file. You can download KNIME update sites as zip files here.
-
Save the zip file containing the extensions to your local system
-
Select File → Preferences → Install/Update → Available Software Sites and enter the path to the zip file by clicking Add → Archive… as shown in Figure 5.
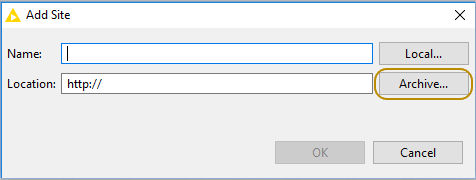 Figure 5. Adding Update Sites from Zip Archive
Figure 5. Adding Update Sites from Zip Archive
| If the same extensions are provided by a URL, you will first have to disable the update site by disabling it in the list. |
-
Now click Apply and Close
| If the same extensions are also provided by a remote update site, you will first have to disable that update site by deselecting its entry in the Available Software Sites dialog and confirming via Apply and Close. |
Working with the Nightly Builds
Once a night, a new version of KNIME Analytics Platform is created directly from our development branch. The Nightly Build versions available here provide insight into what’s coming up in the next regular release. However, for real work, always use a version of a standard KNIME release. Also read the following disclaimer before proceeding:
|
Really, really, really important disclaimer This is most definitely not production quality code. These nightly builds are what we use internally to validate and test recent developments, so they are not tested as thoroughly as standard KNIME releases. Furthermore new nodes or functionality may change substantially (or disappear entirely) from one build to the next. It’s even possible that workflows you edit or create with nightly builds stop being readable by future (or past) versions… These nightlies are a great way to get a sneak peek at what may be coming in the next version of KNIME and provide feedback and suggestions. They are not a particularly safe way to do real work. |
Changelog (KNIME Analytics Platform 3.7)
Detailed changelog for v3.7.x releases
KNIME Analytics Platform 3.7.0
(see highlight summary)
Release date: December 6, 2018
New Nodes
-
AP-10977: XGBoost Integration: Various new nodes integrating the XGBoost machine learning library (Labs)
-
AP-10435: Google Authentication (interactive authentication for Google Drive/Sheets/Analytics/…)
-
AP-8967: Updated Tableau Integration ('Hyper' support — two nodes: Write Hyper file and Send to Server)
-
AP-7812: Histogram (JavaScript)
-
AP-10123: Card View (JavaScript)
-
AP-7811: Hierarchical Cluster Assigner (JavaScript)
-
AP-5181: Heatmap (JavaScript)
-
AP-10036: Kolmogorov-Smirnov Test (statistical hypothesis test)
-
AP-9010: CSS Editor
-
AP-10976: Database Integration (Labs): Rewrite of existing DB client nodes, supporting more connectors (e.g. Oracle, SQL Server), connection pooling, rich type support, powerful editors, etc. (part of KNIME Labs)
-
AP-9938: Friedman Test (non-parametric statistical test)
-
AP-9937: Proportion Test (statistical hypothesis test)
-
AP-9907: Container Input (Credentials)
-
AP-9466: Google Drive Connection
-
AP-10404: Turkish POS Tagger
-
AP-10403: Turkish Stemmer
-
BD-781: (Big Data Extensions): PySpark Script nodes
-
BD-435: (Big Data Extensions): Spark Row Filter node
Enhancements
-
AP-10809: Upgrade bundled H2 database driver to 1.4.196
-
AP-10717: Expression Engine: UI Improvements
-
AP-10673: Consistent background colours for JavaScript scatter and line plot
-
AP-10644: JS views: new aspect ratio setting "square" (1:1)
-
AP-10636: H2O Integration: H2O Scorer nodes should push scores as flow variables
-
AP-10577: Python: Allow Python environment selection via flow variable
-
AP-10529: Container Input (Table) with optional table spec in JSON input
-
AP-10489: Optimize Parquet Dictionary Encoding
-
AP-10451: R Snippet Dialog: Allow eval current line when nothing selected
-
AP-10425: Move Annotations to Back/Front context menu entries
-
AP-10406: Turkish stopword list
-
AP-10397: FileStoreCell: Support for managing multiple FileStores
-
AP-10379: IO Improvements for Keras and Tensorflow
-
AP-10334: Container Input (Table) with new option to expose example table to the API definition based on the input table
-
AP-10292: One To Many node throws misleading error when the domain of the input table contains more than 60 distinct values
-
AP-10268: Python: Jupyter notebook support for Python nodes
-
AP-10262: Improved error message for Call Workflow (Table based)
-
AP-10221: Layout changes to support nested layouts (from nested wrapped metanodes)
-
AP-10220: Nested Wrapped Metanodes behave the same as WizardNodes
-
AP-10218: JavaScript scorer improvements
-
AP-10136: Call Workflow (Table Based) improve invocation naming to reflect actual behavior
-
AP-10075: Upgrade Tika version to latest version
-
AP-10068: Column Expressions: Allow Conversion of DataCells
-
AP-10037: Crosstab: improve default settings for Cross tabulation view
-
AP-10034: Shapiro Wilk Normality Test: support multiple columns
-
AP-10027: Wilcoxon Signed-Rank: compute median per column
-
AP-10026: Statistics Nodes: show p-values with Full Precision by default
-
AP-9845: Hyperparameter Optimization: Random Search
-
AP-9814: Java Snippet to provide meaningful error message in log file
-
AP-9799: Discard after execution option for Call Workflow (Table Based) node
-
AP-9739: Turkish Tokenizer
-
AP-9718: Make Cross Joiner Streamable
-
AP-9610: Make Color Manager able to dynamically update possible values when using Palettes
-
AP-9603: H2O Nodes - Better progress reporting when run with Sparkling water context.
-
AP-9566: Column Expressions: New Functions to read / manipulate / create cell collections
-
AP-9564: Workflow Editor: yellow message bar ("you are editing a remote workflow") always to be pinned to the top of the current view port
-
AP-9526: Cell Splitter with option to guess number of columns based on first rows only
-
AP-9525: Line Reader with option to read first row as column header
-
AP-9524: Cell Splitter: "Split header column"
-
AP-9492: Settings option to issue a warning when a node is replaced/inserted
-
AP-9419: Python: Update Apache Arrow version to 0.10.0
-
AP-9380: Upgrade Excel processing library (Apache POI) to version 3.17 (fixes issues reported in forum)
-
AP-9357: Send Credentials via Call Workflow (Table Based)
-
AP-9273: Retain order of nodes in wrapped metanode layout editor
-
AP-9250: Text Mining: Add possibility to use custom model for OpenNLP tagger
-
AP-9082: Keyboard actions to zoom in/out in workflow editor
-
AP-8997: Lower severity level of "possible deadlock" message detector
-
AP-8853: Tableau: Append to TDE file
-
AP-8638: JS Views bidirectional communication support - core changes
-
AP-8593: More intuitive paradigm to edit and move annotations
-
AP-8470: Python: Allow cancelling data transfer
-
AP-8266: Speed up of parameter optimization loops
-
AP-7939: Re-enable the "Fullscreen" button in javascript views that aren’t running in the WebPortal
-
AP-7561: (API): ColumnRearranger to filter out unused columns when reading reference table (significant speed-up for large workflows when using Parquet table format)
-
AP-7248: "Timer Info" node also recording statistics of nodes contained in meta nodes (non-wrapped)
-
AP-6869: New Date/Time support in Tableau nodes (Hyper only)
-
AP-6139: JavaScript Pie Chart: support selection
-
AP-5352: Cell Splitter with option to replace input column
-
AP-5233: Pivoting node needs column naming options
-
BD-808: (Big Data Extensions): PySpark support for Local Big Data Environment
-
BD-803: (Big Data Extensions): Upgrade "Create Local Big Data Environment" node to Spark 2.4
-
BD-802: (Big Data Extensions): Add Spark 2.4 to KNIME Extension for Apache Spark
-
BD-799: (Big Data Extensions): Support KNIME Workflow Executor for Apache Spark with local big data environments
-
BD-762: (Big Data Extensions): Add type handling support to Parquet reader and writer
-
BD-761: (Big Data Extensions): Add type handling support to ORC reader and writer
-
BD-548: (Big Data Extensions): Support cancelation of wrapped metanodes with KNIME Workflow Executor for Apache Spark jobmanager
-
BD-356: (Big Data Extensions): Selectable job manager for KNIME Workflow Executor for Apache Spark
-
BD-318: (Big Data Extensions): Configurable persistence level of DataFrame created by KNIME Workflow Executor for Apache Spark
-
BD-317: (Big Data Extensions): KNIME on Spark: Add support for ingoing flow variables
-
BD-316: (Big Data Extensions): Support preference import from KNIME Server into KNIME Workflow Executor for Apache Spark
-
BD-128: (Big Data Extensions): Enable arbitrary input ports with KNIME Workflow Executor for Apache Spark job manager
Bug Fixes
-
AP-10873: Bar Chart legend overlaps bins under specific requirements
-
AP-10851: JavaScripts nodes blocking KNIME Server (on Oracle Linux)
-
AP-10834: JavaScript Barchart does cut off visualisation early when stacking is used
-
AP-10800: CTRL SHIFT ENTER does not execute node and open outport view
-
AP-10555: Create Directory node fails
-
AP-10884: XGBoost Locale Problems
-
AP-10876: Resource leak in SftpURLConnection
-
AP-10874: Improve EXAMPLES Server login failure message
-
AP-10853: TagCloud: one word is colored wrong
-
AP-10845: Connection loss when replacing output node in meta-node
-
AP-10839: Default password in credentials input node does not work with REST interface
-
AP-10823: Configuration dialogs of various learner nodes do not update twin list after new target is selected
-
AP-10802: Parameter Optimization Loop Start outputs rounding errors
-
AP-10792: Decision Tree Predictor fails if the input contains a column with the prediction column name
-
AP-10773: Card View: Title & menu take up too much space
-
AP-10756: Random Search: Make use of stepSize
-
AP-10741: Wrapped-Metanode: Input / Output nodes can be deleted after changing port configuration (but shouldn’t)
-
AP-10727: Improve error messages for Download node when file does exist in Google Drive
-
AP-10726: Can’t resize annotations in zoomed in/out workflows
-
AP-10710: No varargs possible for string-functions in Expression Engine
-
AP-10693: Some views do not have full screen buttons
-
AP-10659: JS Parallel Coordinates plot doesn’t respond to selection in a composite view when the RowIds have complex format
-
AP-10654: Random Forest Learner (dialog): When changing target, the old value goes into the 'exclude' list — should be included
-
AP-10653: Container Input (Table) silently accepts invalid input (e.g. "blah" in an int column is represented as missing)
-
AP-10638: "Decision Tree to Ruleset" node fails on boolean splits
-
AP-10569: Column Expressions node not parsing argument correctly when starting with (
-
AP-10547: H2O: Column type lost if passed through node
-
AP-10543: Math Formula (Multi Column) with RegEx throws error
-
AP-10531: Call Workflow node fails to send URI columns to Container IO nodes
-
AP-10528: Strange behaviour of String Manipulation (Flow Variable) node inside of Counting Loop
-
AP-10511: JS Parallel Coordinates: Selection lost when resizing window
-
AP-10447: Wrapped Metanodes invert order of flow variables
-
AP-10434: Column Splitter shows warning if not-enforced columns are not available
-
AP-10419: Range Slider Filter Definition node: Rounding min/max range issue
-
AP-10409: Typo in "Reset not allowed" dialog.
-
AP-10354: Parallel Coordinates plot cuts long labels on the first axis
-
AP-10331: DL Keras: Sequential to Model converting different in Keras 2.2.0
-
AP-10280: MacOS app bundle contains multiple instances of Chromium, resulting in excessive disk usage
-
AP-10279: Integer Overflow in BufferedDataTable’s incrementing IDs
-
AP-10254: Table View does not respond to filters on excluded columns
-
AP-10144: Table Validator does not convert integer to doubles
-
AP-10122: Configuration dialog doesn’t show when KNIME is not the active window on macOS
-
AP-10109: Create Collection Column: typo in the node description
-
AP-9943: Javascript Box Plot cuts long label names on y axis.
-
AP-9871: Metanodes in Wrapped Metanode will fail without reason under detailed circumstances.
-
AP-9775: Automatically connect DL nodes in the workflow by double clicking the node in Node Repository
-
AP-9669: DL Keras: Node Generation Spinner Widget Bugs
-
AP-9628: Workflow Editor: Replacing a node destroys customized link geometries
-
AP-9581: Node (Un)Linking Hot Buttons do not work with Metanode boundaries
-
AP-9455: H2O Integration: Stratified Partitioning problem (missing token, incorrect number of arguments, …)
-
AP-9247: Create FileStore Column in LoopEnd causes test workflows to fail
-
AP-9167: String Manipulation (Variable) displays incorrect default value for "Replace Variable" when one has been set already.
-
AP-8973: Unexpected display behavior when choosing filepath in quickform
-
AP-8923: Tableau Server node description refers to Visual Basic 2013, but links to Visual C++ 2013
-
AP-8711: H2O Cluster Assigner Duplicate column names
-
AP-8126: Column aggregator needs to handle duplicate column names
-
AP-8114: Excel Reader produces wrong output for Japanese characters
-
AP-7592: File Reader fails on spaces in URL (should handle gracefully — e.g. when using knime:// URLs)
-
AP-5759: Weka 3.7 splash icons not shown
-
AP-5653: JavaScript Box plot does not handle special doubles correctly (Nan and infinity)
-
AP-5245: Naive Bayes Predictor: numerical problems with close-to-0-variance attributes + predicted probabilities slightly off according to PMML standard
-
AP-4780: kNN node creates non-standard names for probability columns
-
BD-806: (Big Data Extensions): Prevent IO in configure of FileFormatWriter/ReaderNodeModel
-
BD-778: (Big Data Extensions): Spark SQL port causes unpersisting of cached DataFrame
KNIME Analytics Platform 3.7.1
Release date: January 29, 2019
Enhancements
-
AP-11007: DL Framework: Add simple summary view to DL Port Objects
-
AP-10984: Rename "Card View" node to "Tile View" (otherwise infringing trademark held by 3rd party)
-
AP-10560: Update deprecated node of Cross Validation metanode
Bug Fixes
-
AP-11264: Sorting table in table view causing documents to be shown as missing values
-
AP-11212: FileChooser doesn’t work in WebPortal with Firefox
-
AP-11181: Refreshing parts of the workspace after workflow rename take longer than in 3.6
-
AP-11174: R integration: Columns are not kept if an empty table is returned from R to KNIME
-
AP-11032: Mountpoint gets deleted upon restart if it was set to inactive
-
AP-11031: Expression Engine: Scrollbar does not resize/appear
-
AP-10959: Expression Engine: min, max doesn’t support Date&Time anymore
-
AP-11222: H2O Integration: Scorer node mixes up columns in the confusion matrix
-
AP-11192: Map Oracle type Date to local date time and not local date
-
AP-11182: Row Filter framework might cause problems during UI component initialization
-
AP-11162: "Table Row to Variable Loop Start": Table iterator leak making KNIME slower and slower for large number of iterations/tables
-
AP-11151: More SWT Windows handle leakage
-
AP-11124: DL Keras: Recurrent layers are broken
-
AP-11063: Cell Splitter by Position node checks wrong settings for column name duplicates during configuration
-
AP-11055: XGBoost Learner: Column moves from excluded to included on dialog reopen
-
AP-11049: Workflow editor missing after trying to maximize workflow
-
AP-11042: H2O Predictor nodes do not set a default column name in the dialog as other Predictor nodes do
-
AP-11041: DL Network Executor fails in streaming mode with Round Double node
-
AP-11039: Clean up dangling SWT handles
-
AP-11019: RegexMatcher in Expressions returns String
-
AP-11018: Text Mining: Tag Filter does not work properly with Zemberek Tags
-
AP-10982: Open workflow fails if db session for executed nodes can not be restored and thus does not exist
-
AP-10975: Tensorflow Extensions claims ownership of 'org.knime.base' — nodes are possibly associated with this feature in the node description/usage records
-
AP-10947: R version detection reports invalid installation when Rserve (or any other dependency) is missing
-
AP-10912: DB Connector node should update type mapping when database type changes
-
AP-10891: Send Email waiting endless for email server response
-
AP-10735: DL TensorFlow Reader: Error console output during typing
-
BD-883: (Big Data Extensions): Spark Entropy Scorer fails with NullPointerException on missing values
-
BD-878: (Big Data Extensions): PySpark Snippet nodes fail in local big data environment on Windows
-
BD-776: (Big Data Extensions): Unpersist Spark DataFrame/RDD node makes DataFrame/RDD unavailable
-
BD-655: (Big Data Extensions): Spark GroupBy fails on numeric aggregations for boolean columns
-
BD-654: (Big Data Extensions): Spark Scorer should ignore rows with missing values
-
BD-653: (Big Data Extensions): Spark Collaborative Filtering Learner dialog should not allow boolean columns as user or product columns
-
BD-630: (Big Data Extensions): Spark Category to Number fails on missing values
KNIME Analytics Platform 3.7.2
Release date: April 18, 2019
Enhancements
-
AP-11412: DevDoc: Write a new KNIME Node Extension Quickstart Guide
-
AP-11261: (API) Add hook to workflow loading routine to populate "knime.system.credentials"
-
AP-9412: Add new regions to AWS S3 Connector node
Bug Fixes
-
AP-11596: Import preferences does not properly import mountpoints
-
AP-11531: Changing Multi-line editor width in String input Quickform does not work in 3.7
-
AP-11488: H2O confuses column name order when used with Spark Context
-
AP-11399: Error when input table is empty for "Row To Variable Loop Start" node
-
AP-11370: H2O Integration: Dialog of Table to H2O node does not work anymore
-
AP-11367: Column Enforce Inclusion/Exclusion Bug in Multiple Learner Nodes
-
AP-11583: POST Request node 'request body' configuration problems
-
AP-11580: H2O Integration: Typo in "H2O Multinominal Scorer"
-
AP-11577: KNIME Table API: RowIteratorBuilder not 'future proof' (will be removed from API and redone in 3.8)
-
AP-11530: Tile View (JavaScript) does not display SVGs in WebPortal
-
AP-11525: Stacked Area Chart assigns colors based on column order instead of column name
-
AP-11479: Network Viewer (JavaScript) Nullpointer Exception
-
AP-11466: Post Request nodes forgets URL settings on load
-
AP-11459: Send to Tableau Server (Hyper) node is not performing overwrites correctly
-
AP-11364: Dead link in OPTICS Cluster Assigner node description
-
AP-11359: 'POST Request node' - settings can throw java exceptions
-
AP-11356: Early stopping of Random Search does not work properly in certain cases
-
AP-11347: H2O scorer nodes fail with unmeaningful error messages if reference column contains missing values
-
AP-11342: Continued SWT leak hunting
-
AP-11317: JavaScript Histogram View fails on missing values
-
AP-11271: Missing Whiskers in Boxplot (JavaScript)
-
AP-11155: Java Snippet node configuration dialog loads awfully slow
-
BD-905: (Big Data Extensions): Hive to Spark/Spark to Hive do not work on HDP 3.x
-
BD-901: (Big Data Extensions): Adding flow variables in PySpark node breaks preset text areas
-
BD-900: (Big Data Extensions): Spark to H2O fails on 'Short' columns
-
BD-844: (Big Data Extensions): Fix column spec domain in Table to H2O Node with Sparkling Water Context
-
BD-838: (Big Data Extensions): Spark to H2O node only works with H2O Sparkling Water Context, configure fails with bad error message